 * think of an example; Newton's Method for
single-vbl fn ... **
* think of an example; Newton's Method for
single-vbl fn ... **A neural net consists of a set of inputs, a 'black box' containing one or more adjustable parameters and a rule or set of rules for applying these parameters to the inputs. The rule that governs the behavior of the 'black box' is nonlinear with respect to the inputs.
A training set consists of a set of training inputs along with the ideal output(s).
To train the network the values of the parameters in the 'black box' are adjusted until the output that results from the training inputs is sufficiently close to the desired output.
Here we let X stand for the set of training inputs and Y for the ideal output, with C(0) a matrix of parameters:
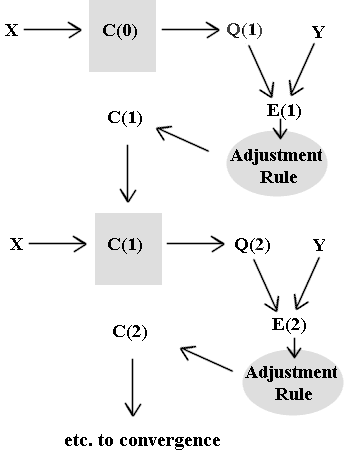
Oversimplified version:
An oversimplified schematic might be the one shown below, where training input X is fed into the 'black box' with parameters C(0), which yields output Q(0).
This process is iterated until the convergence criterion, whatever it happens to be for the specific process, is met.
* think of an example; Newton's Method for
single-vbl fn ... **
Our model:
In the model we're going to consider here we break down the 'black box' into a set of 'neurons', each with a number of synapses. Each synapse of each neuron has a strength. Neuron strengths are the parameter in our matrices C( ).
X will stand for a set of N training vectors, each with m components. The ith vector will be denoted x(i), and its components x(i, j) with j running from 1 to m. Thus X can be represented by the N x m matrix depicted below.
We assume a number N of neurons equal to the number N of training vectors. The output of each neuron will be a single number y(i).
Our ideal output Y will be a vector consisting of N components y(i), as depicted below.
Each neuron will have m parameters, one for each component of an input vector. Thus C(0) can be represented for all neurons as an N x m as a matrix C(i,,j,0), with each column representing the parameters for a single neuron. The jth neuron will be represented by the jth column of this matrix:
In this model we will train one neuron at a time so we need not consider the entire matrix C(i, j, 0). We will denote the jth column of the matrix C(i, j, 0) by Cj (i, 0). This column vector will be modified with consecutive iterations to give us Cj (i, 1), Cj (i, 2), ..., Cj(i, k), ... .
The ith row of the X matrix corresponds to a single vector x(i, j), where j runs from 1 to m. We first consider the action of the first neuron on the vector x(i, j).
For simplicity we will assume that our neuron first simply multiplies the input row vector by the column vector consisting of its parameters, obtaining the sum
Repeating this for all N input vectors we obtain a row vector [ Sj x(i,j) * c1(j, 0), 1 <= i <= N ]
To each sum Sj x(i,j) * c1(j, 0) we apply a nonlinear transformation to obtain f1(i), obtaining the vector
This vector is the output of the first neuron of our 'black box' corresponding to our input training matrix X and our initial parameters C1(j, 0). This vector is a vector in N-dimensional real space.
We will train our neurons one at a time. Each neuron will will act on the entire training set to produce output Q(i), where i is the number of the neuron, and will
Our more specific procedure is represented by the schematic below:
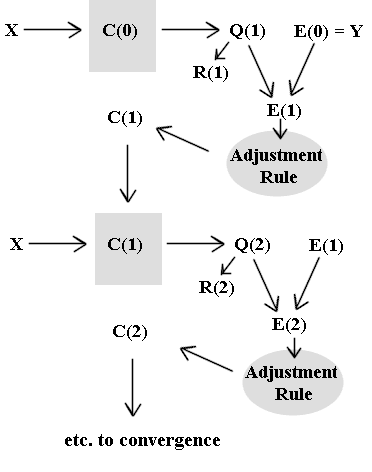
The motivation for this approach:
The vector Q(1) will be taken to be our first basis vector
The initial error E(0) will be taken to by our ideal output Y.
We project the error E(0) on R(1). The scalar projection is
and the vector projection is found by multiplying the scalar product by the unit vector in direction of R(1)
Our error vector is at this point E(1) = w1 R(1) - Y.
We adjust our parameters C1(j, 0) to try to reduce our error:
What we end up with is the Jacobian of E(1) with respect to the parameter set C1(j, 0). This sounds pretty horrible but it's fairly straightforward, assuming our nonlinear transformation involves a function of which we can take derivatives (e.g., affine transformation, exponential functions, sigmoidal functions etc.). If not we could probably vary our parameters C1(j, 0) and see how E(1) changes, obtaining useful approximations.
We then penalize any parameter that tends to increase E(1) and reward any parameter that tends to decrease E1. We also avoid significant-figure errors by penalizing small R(1).
The specifics:
A single input into a single neuron
let X stand for the set of training inputs and Y for the ideal output, with C(0) a matrix of parameters:
Preliminary development in 3 dimensions.
We start with 3 input vectors, our 'training inputs', arranged here as rows in a matrix. Each vector in this example has dimension 4 so the matrix has dimension 3 x 4. However this dimension is arbitrary, as is the number of input vectors. We let X stand for the matrix and x, for the vectors:
training matrix: X = [x1, x2, x3, x4]T = [[x11, x12, x13, x14], [x21, x22, x23, x24],[x31, x32, x33, x34]].
In general our training matrix will be N x m, consisting of N training input vectors each of dimension m.
Each of the training inputs xi has an ideal output, which is a real number yi. Our output vector is therefore
Y = [y1, y2, y3]T,
represented here as a column vector.
In general if there are N training input vectors Y will be an n-dimensional vector.
We have a 'hidden layer' of N neurons, one for each training input vector.
Each neuron can be thought of as a 'black box' with m parameters which can be represented as a column vector [c1, c2, ..., cm] whose dimension matches that of a single input vector. These parameters are initially random within some appropriate range. To distinguish the parameters for one neuron from those for another we will use an additional subscript i corresponding to the number of the neuron: [ci1, ci2, ..., cim] is the current set of parameters for the ith neuron. These parameters correspond to synapses. ** For the current example m = 4. **
** it looks here as though we need three subscripts, one for the neuron, one for the position in the vector, one for the training level k. **
We will begin by training the first neuron. This is done through a series of iterations, with each iteration strengthening (increasing) or weakening (decreasing) each individual synapse depending on whether its effect is to move us toward or away from our goal. The training of this and of each subsequent neuron will cease when our output is considered to have converged--to have either stopped changing significantly or to have approached a given state to a prespecified level of precision.
We might therefore think of the synapses as being triply-subscripted variables cijk, with i standing for the number of the neuron, j for the position in the m-dimensional vector corresponding to that neuron, and k the number of the current iteration.
We will first think of training our first neuron and will simplify notation by denoting that neuron's parameters, or synapse strengths, as c1 =[ c11, c12, ..., c1n]. We note that the matrix X is compatible for multiplication by the column vector [c11, c12, ..., c1m].
To obtain the output of our first neuron we first use our randomly generated values of the c1j.
** we might in applying the Gaussian use sum(xi - ci)^2 / (2 * std dev) **
We will use each of the three neurons in our three-input case to 'train' the output to minimize the component of the error in one of the three linearly independent directions of 3-dimensional space.
We might use a simple affine transformation of the product. We obtain X c1 = S ( xij c1j) and we simply add the arbitrarily chosen constant vector [1, 1, 1] to our result to obtain Q = [ S ( xij c1j) + 1 ]. Other common transformations include **
The details are not at this point important. However we should understand that our result Q will be a vector with 3 components, which we think of as represented with respect to a standard 3-dimensional Cartensian coordinate system, along with our ideal training output Y.
Since our parameters c1j were generated randomly it is not possible that Q will be equal to Y. We in fact expect that the magnitude and direction of Q will be unrelated to those of Y. Let R1 = Q . We will minimize the error Q - Y in the direction of R1 . We now project Y on Q , obtaining the vector projection ** use DERIVE **
Annotated training algorithm.
The My notation is a bit cumbersome but should be fairly obvious. My comments will often be obvious to you, but if they are correct they should be directly adaptable into code or pseudocode.
I also looked up some information on the conjugate gradient method of adjusting parameters, which adjusts the things in a set of mutually orthogonal directions to avoid possible oscillations of the solutions in a 'long, narrow well', where the curvature in one direction is much greater than in another, causing the parameters to bounce around off the closer walls and converge to the desired minimum very slowly. I don't have details I can probably figure out how to implement such a beast, but will confine comments here to the gradient descent method.
I've said more than you might need to just implement the thing, especially under the constraints of time. I've given a bit of the geometric interpretation, which might or might not be helpful to you. I can go into more detail there but didn't want to bog down the information about the implementation. Program from a room to
You start with an array of N training data, which consist of a set of N input vectors each of form X = [ x1, ..., xm }T, and a desired output y. The outputs form the N x 1 array Y.
Step 1
E0 = Y
Scale E0
Initialize C1 as C(1,0)
k = 0
Repeat
Calculate Q1
R1 = Q1
w1 = E0T * R1 / || R1 ||^2
C(1, k+1) = C(1,k) - correction term
k = k + 1
Until Convergence
Test the network on testing data
Check stopping criteria
If adequate, stop
Else, proceed to next step.
Step n
Scale E(n-1)
Initialize Cn as C(n,0)
k = 0
Repeat
Calculate Qn
`alpha(i,n) = RiT Qn / || Rn ||^2
Rn = Qn - sum(`alpha(i,n) Ri)
wn = E(n-1)T * Rn / || Rn ||^2
C(n,k+1) = C(n,k) - correction term
k = k + 1
Until Convergence
En = E(n-1) - wn Rn
test, check, etc.