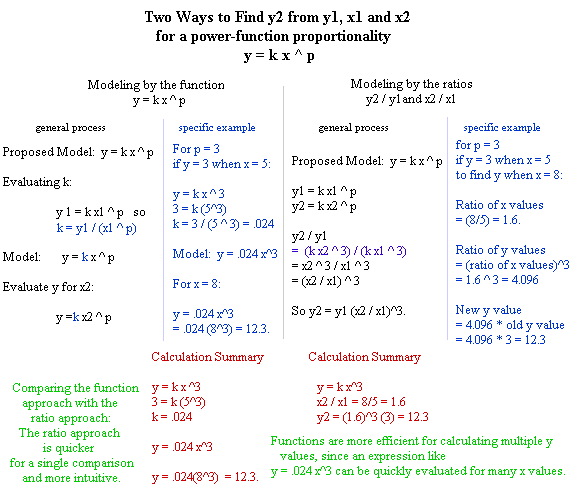- Finding the first several values of a(n)
- Modeling a(n) with a quadratic function
- Analyzing the pattern of the sequence a(n)
- Suggested Exercise
- Slopes (rates) change at a constant rate
- Suggested Exercise
- The function approach vs. the ratio approach
- Suggested Exercise
Finding the first 5 values of a(n)
We are given a(n+1) = a(n) + 5 n, a(1) = 2. We let n = 1, 2, 3, 4 and 5 and see what this definition tells us:
n=1:
a(1+1) = a(1) + 5 * 1
a(2) = 2 + 5*1
a(2) = 7
n=2:
a(2+1) = a(2) + 5 * 2
a(3) = 7 + 5*2
a(3) = 17
n=3:
a(3+1) = a(3) + 5 * 3
a(4) = 17 + 5*3
a(4) = 42
n=3:
a(3+1) = a(3) + 5 * 3
a(4) = 17 + 5*3
a(4) = 32
n=4:
a(4+1) = a(4) + 5 * 4
a(5) = 32 + 5*4
a(5) = 52
Modeling a(n) with a quadratic function
Solving the system of simultaneous equations for the data points (1,2), (2,7), (3,17), or using FIT([x,ax^2+bx+c], [ [1,2], [2,7],[ 3,17] ] ) we obtain the quadratic model
quadratic model for first three points (n, a(n)): a(n) = 2.5 n^2 - 2.5 n +2.
If we find a(4) and a(5), we obtain
a(4) = 2.5 (4^2) - 2.5(4) +2 = 32
and
a(5) = 2.5 (5^2) - 2.5(5) + 2 = 52.
It turns out that every a(n) obtained from the recurrence relation a(n+1) = a(n) + 5 n, a(1) = 2 matches the a(n) of the function a(n) = 2.5 n^2 - 2.5 n + 2. We say that the function is a solution of the recurrence relation.
The pattern of the sequence
If we look at the sequence behavior of the a(n) values 2, 7, 17, 32, 52, …, we see the following pattern:
It is clear from the definition of the sequence that the difference between a(n) and a(n+1) is 5n, since a(n+1) = a(n) + 5n. This is clear in the second line, where the differences are 5, 10, 15, 20, …. For n = 1, 2, 3, 4, …, these are the values of 5n.
This difference, 5n, increases as n increases. Every time n increases by 1, 5n increases by 5. This is clear from the third line, where the differences of the 5n sequence of the second line are always 5.
Suggested Exercise:Suppose that the recurrence relation was a(n+1) = a(n) - 2 n, with a(1) = 25. Before doing any calculations:
Predict the constant value to be obtained for the second difference.
Predict the shape of the graph of a(n) vs. n.
Now repeat the entire analysis for this recurrence relation: Find the first 5 points, obtain a quadratic model from 3 points and check it for the other two points. Then do the sequence analysis and, if you have not already done so, plot a graph of the function to check your prediction.
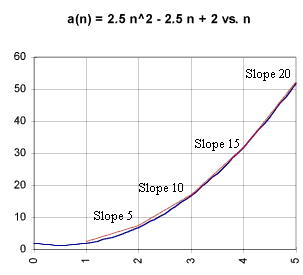
Calculating the slopes between points (1, 2), (2, 7), (3, 17), (4, 32) and (5,52) we obtain slopes 5, 10, 15 and 20. These slopes match the differences found in the preceding example.
The red lines on the graph below depict straight lines between graph points. Slopes are indicated above the lines.
This slope behavior is typical of quadratic functions. The slopes, or rates, calculated between equally spaced values of x change by a constant amount.
Thus we say that the rate changes at a constant rate.
This behavior would be found with any set of constantly spaced x values. For example, we could evaluate the function at x = 1, 1.5, 2, 2.5, 3, …, with x values spaced by .5 instead of 1 as before, to obtain y values 2, 3.875, 7, 11.375 and 17. The corresponding slopes or rates of change are
(3.875 - 2) / .5 = 3.75
(7 - 3.875) / .5 = 6.25
(11.375 - 7) / .5 = 8.75
(17 - 11.375) / .5 = 11.25
The changes in the slopes are
- 3.75 = 2.5
- 6.25 = 2.5
- 8.75 = 2.5.
These slopes change by 2.5 each time. Note that the change is half as great as before, when x was changing by 1.
By how much do you think the rates would change if x was evaluated at intervals of .1?
Evaluate the above function for x = 1, 1.1, 1.2, 1.3 and 1.4, and calculate the corresponding rates. Do the rates change by the amount you predicted?
The figure below summarizes how to predict a value y2 from values y1, x1 and x2, when y and x are related by a power-function proportionality of the form y = k x ^ p.
The left half of the figure shows how we evaluate k from a known 'data point' to get our model y = k x ^ p; the numerical example uses p = 3 and takes known values y = 3 when x = 5 to obtain the model y = .024 x^3. This model is then used with x = 8 to find the corresponding y value y = 12.3.
The right half shows how to use the ratio x2 / x1 to obtain the ratio y2 / y1. In the numerical example the x ratio is 1.6. The p = 3 proportionality dictates that the y ratio must be 1.6 ^ 3 = 4.096, from which we find the new y value 4.096 * 3 = 12.3.
At the bottom of the figure we compare the advantages and disadvantages of the two methods. The first method, called the 'function method', requires more calculation the first time a y value is estimated, but provides an easily-evaluated function (y = .024 x^3 in the example) which can then be very quickly evaluated for as many x values as desired.
The second method encourages us to think about ratios and how x ratios are related to y ratios. This sort of proportionality thinking is very important and very powerful. It also is the quickest way to make a single y estimate. However, we have to go through the whole process again if we want to make another y estimate, so the function model is probably quicker for 2 or more estimates.
** Small, faded version of above: **
Use a p = -2 power function model, with x1 = 3 and y1 = 7, to find the y values corresponding to x = 4, 5 and 6. First use the function approach, evaluating k then plugging x = 4, then 5, then 6 into the resulting function. Next use the ratio approach, calculating the x ratio for each value of x, using this to find the y ratio, and finally finding the desired y value. Comment on the relative efficiency of these approaches.